

Introduction
In 2016, Google released the definitive book on Site Reliability Engineering (SRE) - a practice that had originated in the company to take care of a monumental problem - how to keep the Google services running with high reliability. Over the years, SRE has been widely adopted by dev teams across the globe and is a popular role at startups and enterprises alike.
Here is a look at how search for SRE has trended over the years.
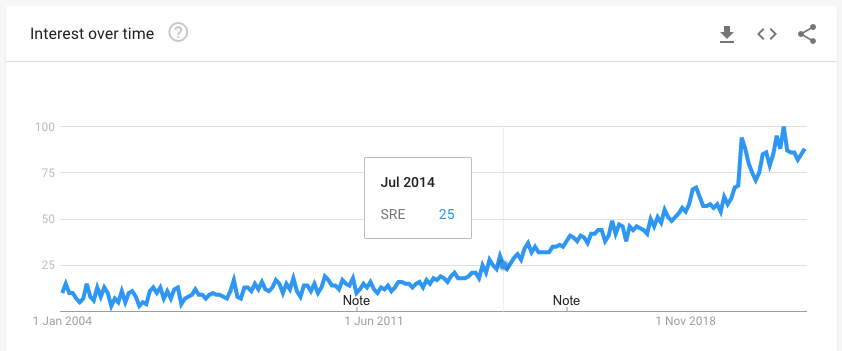
But as with any new practice, we are still building an understanding about what SREs should actually do. What responsibilities are core to the role? And while we can read books and watch videos to understand it, it does not paint a clear picture of what is expected of SREs in a normal day or week.
So we decided to analyse job descriptions for SRE roles from major companies and compile the top responsibilities of the role. Here’s the result of analyzing 30 job postings for SRE from major companies like Google, Twitter, Slack and more.
Findings
Here are the key SRE responsibilities that we identified from the job descriptions.
- Deploy and maintain infrastructure (mentioned in 84% of job descriptions)
- Define and manage SLO, SLI and error budgets (34% of job descriptions)
- Setup monitoring and alerts (47% of job descriptions)
- Be on call, respond to incidents and conduct post-mortems (47% of job descriptions)
- Build tools and automations (56% of job descriptions)
Deploy and maintain infrastructure
One of the important responsibilities for SRE is to design, build and maintain the infrastructure on which the company runs its products and services. This can involve working with self hosted cloud, but obviously hosting with public clouds like AWS and Google Cloud is becoming more common. One popular way is writing infrastructure-as-code with YAML and HCL (for Hashicorp products like Terraform).
To help make the right decisions for infrastructure, SREs will be involved in capacity planning for new and existing products - this involves discussions with the product and engineering teams to estimate the load and understand the thresholds for latency etc.
Some roles expect SREs to make sure that the infrastructure meets compliance requirements. This is especially important for maintaining compliance with leading standards like GDPR and SOC2. Finally, with rising technology costs at most companies, cost optimization of infrastructure is also becoming an important requirement for SREs.
Define and manage SLO, SLI and error budgets
Maintaining reliability of production systems is an important part of SRE, I mean it’s in the title of the role itself. As such, defining what constitutes a service which is running correctly and upto internal standards becomes crucial.
As an SRE, you will be involved in creating SLO and SLIs for this purpose. Service Level Objectives (SLO) specify the target levels for the service, and Service Level Indicators (SLI) help measure the service levels. The SLOs can be derived from internal discussions about customer expectations and any external promises made to the customers in the form of Service Level Agreements (SLA).
Once the SLOs are defined, they can be used to come up with error budgets, or the allowed time that the service can be below the target level. Error budgets give dev and SRE teams some leeway, because a service can never be run at 100% reliability. These budgets can also be helpful for measuring the impacts of incidents e.g. if an incident consumes 30% of the budget, it can be labeled as a major incident.
Setup monitoring and alerts
Once the team has defined SLOs, it is time to track if you are meeting those by defining SLIs (Service Level Indicators) and setting up monitoring for the same. The most common monitoring will be for infrastructure (CPU, memory spikes), service uptime (of website, APIs), performance (page load speed) etc. You will use self hosted tools like Prometheus and Grafana, or use popular SAAS vendors like Datadog and Sentry.
Setting up monitoring and alerts is just the first step. You will also need to make sure that the monitoring thresholds are correct so your team is not overwhelmed with unimportant alerts. You will also need to make sure that the alerts are actionable. And finally, a good alerting system will also make sure to alert on symptoms so actions can be taken, and not after outages happen.
Be on call, respond to incidents and conduct post-mortems
Once you set up monitoring and have alerts coming in, your team will set up on-call schedules so that the load of responding to alerts at all times can be distributed across the entire team. You will be expected to use an incident management platform to ensure that all incidents and alerts are managed in one place, and there is clear ownership attached to every incident. This will also help you in calculating important metrics like MTTA (Mean Time To Acknowledge) and MTTR (Mean Time To Resolve).
You will also be involved in conducting post-mortems so you can explain to internal and external stakeholders about the sequence of events leading to the incident, the remediation steps taken to resolve and changes made to prevent similar issues in the future.
Build tools and automations
One of the core principles of SRE is to “eliminate toil”. Google SRE defines toil as “manual, repetitive, automatable, non-tactical” work that sucks up the time of dev and SRE teams and slows down other important projects. As such, building automation for repetitive tasks is one of the more important parts of the SRE role. The automation could be around responding to common alerts, setting up the CI/CD process so your team can move faster or creating products to enable dev teams to self-service common requests.
Other responsibilities
Depending on the company, some other responsibilities of SRE may include -
- Debug production issues. At some roles, you will be involved in debugging production issues across all levels of the stack.
- Develop multi-cloud strategy. As companies start moving more workloads to public cloud, there is a push to be vendor agnostic for both cost and reliability purposes. Which is why many companies are working on building a strategy for making their products work across different cloud platforms.
- Chaos engineering. Chaos engineering was first pioneered by Netflix, and since then has become a growing practice across more tech companies. It usually involves purposely breaking your systems in surprising ways to see how resilient they are.
Conclusion
As you can see, SRE role is more than just infrastructure maintenance or helping with CI/CD. The goal of keeping your services running at a high level can touch many different areas of operations and software engineering - if that sounds exciting, you should look into SRE.
If you'd like to know more about how Spike.sh can help SRE teams, drop us an email.
References
We looked at the job descriptions from the following companies - Google, Gitlab, Instacart, Oracle, Twitter, Slack, Coindesk, Fastly, Reddit, Datadog, Frame.io, Doordash, Coinbase, MongoDB, Patreon, Box, Away, Adyen, Pinterest, Figma, Apple, Twilio, Airbnb, Squarespace, Robinhood, Mastercard, Spotify, Peloton, Duolingo, Tiktok