
In the past, our yearly recaps were mostly about numbers. What we shipped, how much Spike grew, and a long list of stats. See past recaps: 2023, 2024.
But 2025 felt different to me.
It had many moments that shaped how Spike as a product and the company looks today. Some of them were exciting. Some were uncomfortable, and all of them changed how I think about building Spike.
We’re still bootstrapped and operating lean, with a team of fewer than ten people. And we’re still moving fast—sometimes faster than we should, and often slower than anticipated.
This year, we welcomed new teammates who raised the bar for Spike. Sreekar joined us to kick-start our marketing efforts and help Spike reach the right audience. Ritik joined our engineering team and quickly became part of the core group. I am very happy they both decided to join our team at Spike!
This post is a look back at 2025—across product, people, content, and culture—and a quiet thank you to everyone who has trusted Spike with their incidents this year.
Table of Contents
Building what matters
In 2025, we stayed focused on Spike’s core areas: better alerts, a more flexible on-call setup, and making incident management easier overall.
Designing alert flows, alert rules, and escalations continued to dominate most of our discussions and attention this year. We made many small decisions in this area, and almost all of them had an outsized impact on how Spike behaves when it matters.
Every change we shipped went out through our changelog to our users’ inboxes, and they read and replied with feedback that has greatly mattered to us. Roughly around 75% of the features we released this year came directly from user suggestions, and I’m deeply grateful for that. Thank you!
Toward the end of the year, we shifted our attention more heavily towards on-call. As our user base grew in 2024, we received a lot of feedback around how difficult it was to set up on-call flexibly during the holidays. Honestly, at the time, we were late to fully act on it. Over the course of 2025, though we worked towards closing that gap, and in the last quarter, we implemented many of those long-standing requests so teams could go into the holidays better prepared. After releasing, we got even more feedback.
I must take a moment to mention the strong adoption of Spike’s mobile app in ‘25. For many teams, the mobile app became a primary way to interact with Spike during incidents, and rebuilding it gave us a stronger foundation. We rebuilt the app from the ground up. It was a hard decision to take, but the effort paid off many times over.
Hands-on events

Four weeks after Sreekar joined Spike, he and I realized we needed to do more hands-on sessions so users could make the most out of Spike. For the first time, we set up small, monthly events to walk through key features and answer questions live. We ran two sessions over the year, and we will continue to do more going forward. I personally enjoyed these sessions.
Walking through the product and answering questions firsthand was incredibly rewarding. Although participation was modest—and that’s okay—we started this as an experiment. What mattered more was that people showed up and left with more clarity. That was enough for us to keep going.
Writing with intent
We took writing seriously in 2025.
Sreekar spent weeks debating and writing what we believe are some of the most thoughtful PagerDuty and OpsGenie alternative pieces on the internet. We were very clear about one thing from the start: we did not want to publish mindless listicles. PagerDuty and OpsGenie are respected products, and we respect them too. Since Atlassian is shutting down OpsGenie, we have also covered a huge ground with Jira Service Management as well
Sreekar went deep by signing up, testing, comparing features, and then coming back to debate every detail with us. We spent days discussing what mattered, what didn’t, and how to present our perspective honestly. The result was not a generic comparison, but an opinionated one. Largely his opinion, shaped by real use and discussion.
We’re proud of this kind of content. It reflects how we think about Spike—clear opinions that are grounded in experience.
Beyond that, we also published a large massive glossary covering incident response terms from A to Z. We shared these terms over 26 days across Twitter and LinkedIn, one letter at a time. Along the way, our LinkedIn community crossed 11,000 followers. Thank you for reading, sharing, and following along.
First principles for Spike’s culture
I didn’t anticipate how much culture would matter to me when building Spike. For a long time, the only thing I cared about was the product—making Spike the best possible on-call and incident response experience in the world.
Over time, it became clear that building something like that requires more than good engineering. It requires treating the work itself with a certain seriousness. I know, without hesitation, that Spike is the most important work I’ll do in my life. And for everyone on the team today, we believe this is the best work of our lives. That belief shapes how we show up every day.
At Spike, reliability is not a side project. When something goes wrong, we declare an incident early, even when it’s uncomfortable or unclear. We’ve learned a lot along the way—especially about when to act fast and when to slow down—but the default is always responsibility. Our users trust Spike during critical moments, and we take that trust seriously.
Honesty and transparency have become our defaults—especially when things don’t go as planned.
Culture at Spike is still evolving. As we grow, we’re still learning how best to carry these values forward.
Our first offsite


We took the Spike team to Goa for three days of food, beaches, and deep talks about what’s next for incident response.
It was our first time all together. Remote work makes these moments special. We even met Sreekar in person after six months of working together.
We spoke about the future, the OpsGenie migration wave, and how Spike can help different teams. These conversations shaped a lot of what we’re building in 2026.
Spike in Numbers
Here’s a look at how teams used Spike throughout 2025.
Alerts
Spike sent 1,032,206 alerts this year. That’s one alert every 30 seconds. And this is a big jump from last year’s one alert every 3.2 minutes.
And here’s how alerts were split across channels :
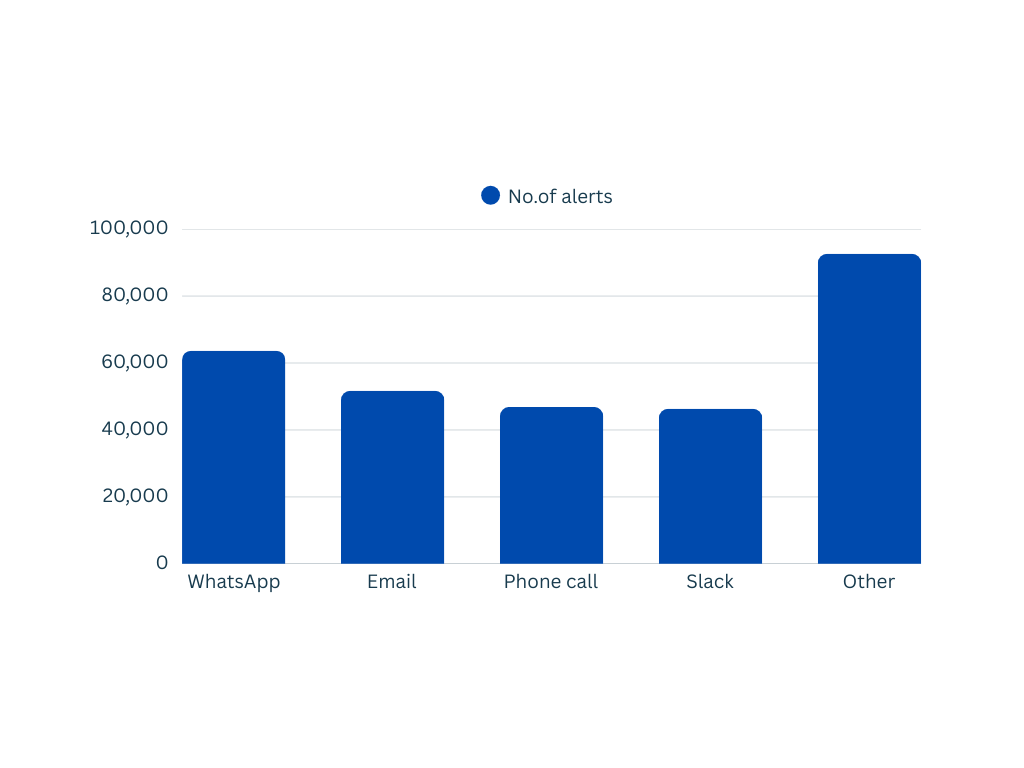
WhatsApp led with 63,697 alerts. Teams want alerts where they already spend their day, and WhatsApp delivers that.
Email came in second with 51,683 alerts. Phone calls hit 46,870, reserved for the moments that truly demand immediate attention. Slack followed close behind with 46,329 alerts.
Push notifications, MS Teams alerts, SMS, Telegram, Discord, and app notifications accounted for the rest.
Incidents
Spike handled 4,069,709 incidents this year. That’s over 11,000 incidents every single day, or roughly 8 incidents every minute. More incidents mean more systems under monitoring and more teams trusting Spike when things break.
Each incident represents a real problem that needed attention. A service that went down, an API that stopped responding, a disk that filled up, or a deployment that failed. Spike caught them all and routed them to the right people at the right time.
On-call
Teams rotated 71,411 on-call shifts this year. That’s up from 53,000 in 2024. A 35% jump that shows more teams adopted structured on-call rotations.
Just like last year, most on-call overrides happened around Christmas and the year-end break.
The growth in total shifts tells that more engineers joined on-call rotations, more services got dedicated coverage, and teams further spread the on-call load.
Marketing
We published 92 new blogs this year. That’s nearly two posts every week. The focus was quality over quantity, with deep dives into incident management, alerting, on-call, and more.
Here are some of our best blogs from 2025 :
- On-Call Schedules: Everything You Need to Know
- Automated Incident Response for DevOps, SREs, and IT Teams
- PagerDuty vs. Spike: Which Incident Management Tool is Better in 2025
- An Ode to OpsGenie: A Look Back at One of Ops’ Most Loved Tools
We also sent 17 changelog newsletters this year. Each one shared new features, improvements, and updates. Changelogs kept users in the loop about what we shipped and why it mattered.
Overall, our marketing efforts in 2025 focused on helping both new and experienced incident managers discover better ways to handle incidents. We wrote for teams searching for alternatives to legacy tools. We kept our users consistently updated through changelogs so they never missed what we shipped. And we built resources like the glossary that serve the entire incident response community, not just Spike users.
Looking Forward
We’re heading into 2026 with a lot of clarity and a lot of energy. We know what matters, and we know where we need to be better.
Thank you for the feedback, trust, and patience you’ve shown us this year. We’re excited to keep building Spike and to put our best work forward as we take the next step.
I’ll see you in our changelog emails. Thanks for reading.